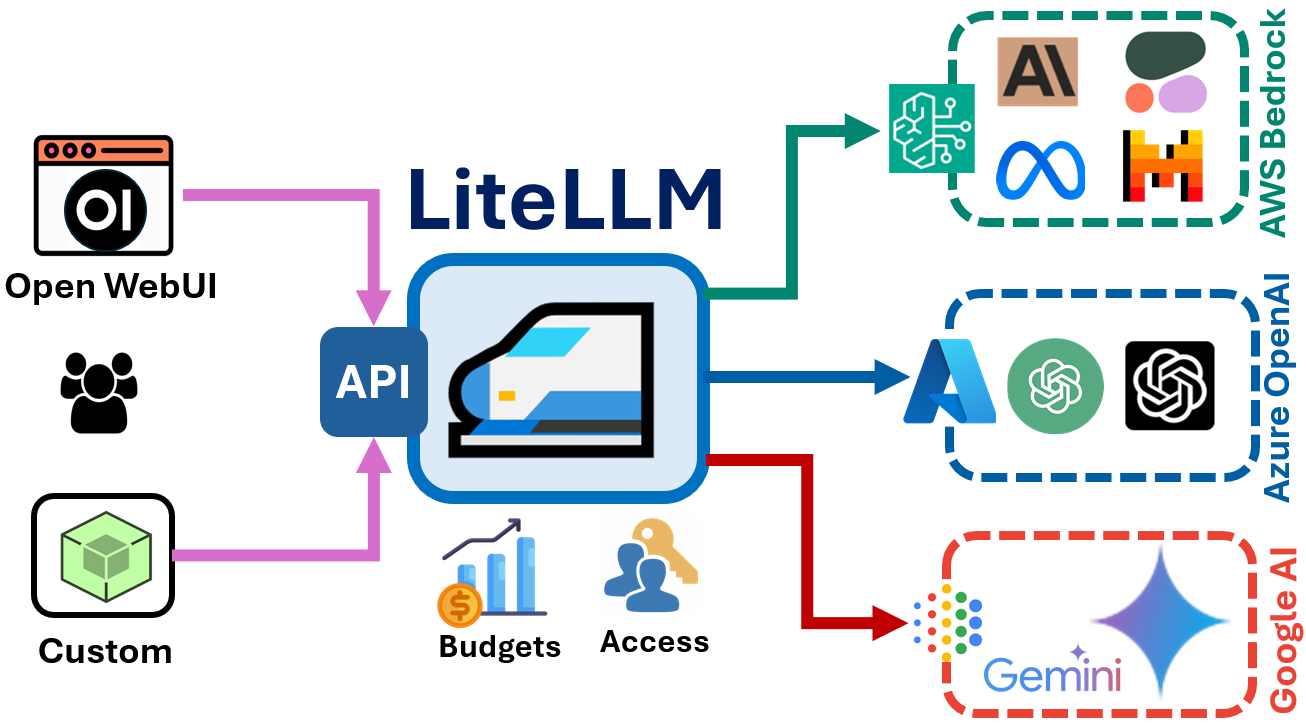
Centralizing Multiple AI Services with LiteLLM Proxy
Creating a centrally managed and secured OpenAI compatible API endpoint with seamless access to multiple AI service providers.
In this article I cover how to setup and configure LiteLLM to access multiple language models from commercial service providers, including OpenAI (via Azure), Anthropic, Meta, Cohere and Mistral AI (via AWS Bedrock) and Google. We’ll cover accessing these services via the proxy API and integrating it with Open WebUI, setting up teams, users, assigning budgets and tracking spend and model utilization.
LitleLLM can be used in two different ways. The first way is to use LiteLLM as an SDK to interact with models and services via code, similar to how other frameworks like Langchain are used. The second way to use LiteLLM is as a proxy server that abstracts multiple services behind a single OpenAI compatible API endpoint. We are going to be covering using it as a proxy.
👉Note: You’ll need to have an account with at least one commercial LLM provider if you wan to set this up for yourself. This includes enabling the services, and getting the endpoints and API keys.
Installing and configuring LiteLLM
LiteLLM can be used as a Python 🐍 package on your system, or via Docker 🐳. For this article we’ll be installing and running LiteLLM via Python. To change things up, I’m using Windows 10 with WSL 2.0 for everything covered here.
First, start by creating a new python virtual environment, activate it and run the following command:
$ pip install 'litellm[proxy]' boto3 openaiAfter this is complete, we need to create a configuration file to define the the services and models we want to access via LiteLLM. Create a file named litellm-config.yaml with the contents similar to the following, adjusting to fit your situation:
# litellm-config.yaml
model_list:
- model_name: gpt4o
litellm_params:
model: azure/gpt-4o
api_base: os.environ/AZURE_API_BASE
api_version: "2024-02-15-preview"
api_key: os.environ/AZURE_API_KEY
- model_name: dall-e-3
litellm_params:
model: azure/dall-e-3
api_base: os.environ/AZURE_API_BASE
api_version: "2024-02-15-preview"
api_key: os.environ/AZURE_API_KEY
- model_name: claude-3.5-sonnet-v2
litellm_params:
model: bedrock/anthropic.claude-3-5-sonnet-20241022-v2:0
aws_access_key_id: os.environ/AWS_ACCESS_KEY_ID
aws_secret_access_key: os.environ/AWS_SECRET_ACCESS_KEY
aws_region_name: us-west-2
- model_name: mistral-large
litellm_params:
model: bedrock/mistral.mistral-large-2402-v1:0
aws_access_key_id: os.environ/AWS_ACCESS_KEY_ID
aws_secret_access_key: os.environ/AWS_SECRET_ACCESS_KEY
aws_region_name: us-west-2
- model_name: llama3.1-405b
litellm_params:
model: bedrock/meta.llama3-1-405b-instruct-v1:0
aws_access_key_id: os.environ/AWS_ACCESS_KEY_ID
aws_secret_access_key: os.environ/AWS_SECRET_ACCESS_KEY
aws_region_name: us-west-2
- model_name: cohere-command-r+
litellm_params:
model: bedrock/cohere.command-r-plus-v1:0
aws_access_key_id: os.environ/AWS_ACCESS_KEY_ID
aws_secret_access_key: os.environ/AWS_SECRET_ACCESS_KEY
aws_region_name: us-west-2
- model_name: google-gemini-2.0
litellm_params:
model: gemini/gemini-2.0-flash-exp
api_key: os.environ/GEMINI_API_KEY👉Note: the Dall-E-3 model I’ve registered above is for generating images, you can’t use it for text inference. In at later section, when we integrate LiteLLM with Open WebUI, you’ll see how it can be used for image generation.
Next, we need a way to register the required environment variables needed by LiteLLM to access the services we defined above. You can accomplish this however you typically do in your environment, but to keep things simple we’ll just use an local .env file. Create a file named .env with the following contents, adjusted to your situation (replace “*********” with your information) and remove services you don’t have):
AZURE_API_KEY=*********************
AZURE_API_BASE=https://************.openai.azure.com
AWS_ACCESS_KEY_ID=*********************
AWS_SECRET_ACCESS_KEY=*********************
GEMINI_API_KEY=*********************
LITELLM_MASTER_KEY=sk-******
PORT=4000
HOST=127.0.0.1The “LITELLM_MASTER_KEY” 🔑 environment variable is something that you just make up; it needs to start with “sk-” to be valid (e.g. sk-1234). We’ll need to use that key to access LiteLLM via the API, to integrate it with Open WebUI and to login to the LiteLLM web UI later in this article.
Next, let’s create a simple script to load the environment variables and start the proxy server. Add the following to a file named start.sh:
#!/bin/bash
export $(cat .env | xargs)
litellm --config litellm-config.yamlLock down the permissions to protect secret variables, make the start-up script executable and prevent the environment variables from accidently being included in a git commit with the following commands:
chmod 600 .env
chmod +x start.sh
echo .env >> .gitignoreWe are now ready to start the proxy; run the following command:
./start-shThe proxy server should now start and provide output that look like this:
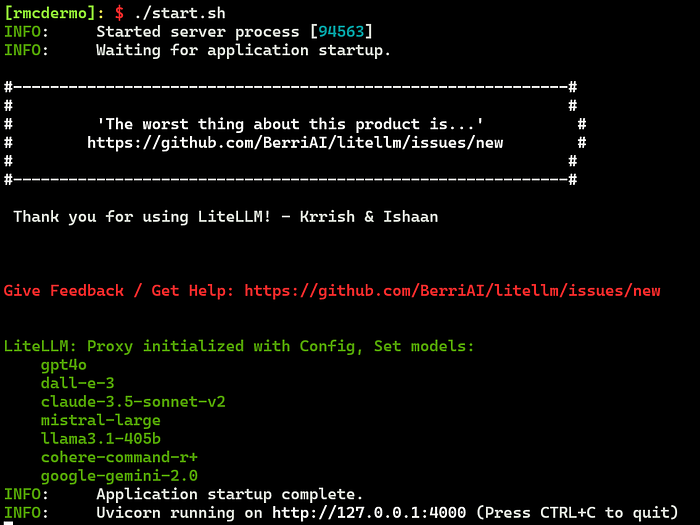
To test that it’s working, you can list all the models you configured with the following curl command (using the liteLLM master key picked):
curl -X 'GET' \
'http://127.0.0.1:4000/v1/models' \
-H 'accept: application/json' \
-H 'Authorization: Bearer sk-******'The output should should be a JSON object that contains and entry for each of the models that you added to the configuration file. The output I received:
{
"data": [
{
"id": "cohere-command-r+",
"object": "model",
"created": 1677610602,
"owned_by": "openai"
},
{
"id": "llama3.1-405b",
"object": "model",
"created": 1677610602,
"owned_by": "openai"
},
{
"id": "google-gemini-2.0",
"object": "model",
"created": 1677610602,
"owned_by": "openai"
},
{
"id": "gpt4o",
"object": "model",
"created": 1677610602,
"owned_by": "openai"
},
{
"id": "mistral-large",
"object": "model",
"created": 1677610602,
"owned_by": "openai"
},
{
"id": "dall-e-3",
"object": "model",
"created": 1677610602,
"owned_by": "openai"
},
{
"id": "claude-3.5-sonnet-v2",
"object": "model",
"created": 1677610602,
"owned_by": "openai"
}
],
"object": "list"
}The LiteLLM proxy should be up and running before moving on to the next sections.
Accessing models via LiteLLM API
LiteLLM has an API that can be used to use the models as well as fully mange and monitor the system. Interactive OpenAPI (Swagger style) documentation is provided by the proxy server by visiting the base of API endpoint, 🌐http://127.0.0.1:4000/ in this article. The OpenAPI documentation site is show below:

Browse the API documentation so you are aware of all the operations that can be automated.
To test LiteLLM, the following script (littellm-test.py) will iterate over a list of models and ask each one of them what their name is:
import openai
import time
# ANSI escape sequence for bright green
BRIGHT_YELLOW = "\033[93m"
RESET = "\033[0m"
models = [
"claude-3.5-sonnet-v2",
"cohere-command-r+",
"llama3.1-405b",
"google-gemini-2.0",
"gpt4o",
"mistral-large"
]
api_key = "sk-***********"
client = openai.OpenAI(api_key=api_key, base_url="http://0.0.0.0:4000")
for model in models:
try:
print(f"\n{BRIGHT_YELLOW}=== Testing {model} ==={RESET}")
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": "What is your name? Keepy your answer brief."}]
)
print(response.choices[0].message.content.strip())
time.sleep(1)
except Exception as e:
print(f"Error: {str(e)}")
continueThe output of this script is shown below. We are getting responses from multiple service providers via LiteLLM’s single API endpoint using the OpenAI dialect:
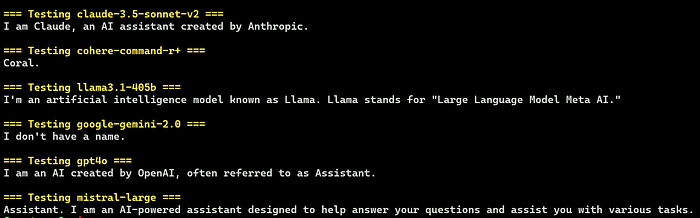
Users, Teams, Budgets and Usage Tracking (optional)
👉Note: This section is optional. If your setup is for person use and you don’t require multiple user accounts, teams, budgets, virtual API keys or cost reporting you can skip this section and go to the next section covering Open WebUI integration.
We can configure LiteLLM to allow us to define user accounts, create and manage teams of users, create and assign spending limits, track spending and set token & request rate limits.
To enable this functionality we need a PostgreSQL 🐘 database. If you already have a database server you have access to you can use that, if not you’ll need to set one up. I’m using WSL 2.0 on Windows 10 to write this article and I installed and configured PostgreSQL as follows:
sudo apt update
sudo apt install postgresql postgresql-contribEdit the “/etc/postgresql/16/main/postgresql.conf” file (your file location might differ) and add the following line:
sudo vi /etc/postgresl/16/main/postresql.configAdd the following line (it probably already exists and just needs to be uncommented). If you database is not on the same server as LiteLLM you’ll need to change this to 0.0.0.0 to expose it:
listen_addresses = '127.0.0.1'Now start the postgres server (I’m running this on WSL so systemctl doesn’t work):
sudo service postgresql start
sudo service postgresql statusThe output of the second command should show that the database is running:

Next we need to create a user and password for LiteLLM. Execute the following command:
sudo -u postgres psql -c "CREATE USER litellm PASSWORD '*****' CREATEDB;"If successful it will respond with “CREATE ROLE”. ✅
Next, we need to add some more variables to the .env file to set a web console username and password, and point LiteLLM to our database server. Add the following three lines to your existing .env file, replacing the masked “*******” sections with a password for the UI and the database user password you set in the previous step.
UI_USERNAME=admin
UI_PASSWORD=********
DATABASE_URL=postgresql://litellm:******@127.0.0.1:5432/litellmOne last thing we need to do before we can restart the liteLLM proxy is install the “prisma” python model in the python virtual environment we’ve been using for this project.
pip install prisma👉Note: installing prisma on Linux, MacOS and WSL was simple, but if you are doing this on Windows, outside of WSL, pip will need the Visual Studio C++ build tools. If you are using Windows, it’s best to save yourself some trouble and stick with WSL 2.0.
We are now ready. Stop the proxy (Ctrl-C) and start it again with the start.sh script we created. This time you should see some extra output as it is creating the database and tables.
🌐Point you web browser to http://127.0.0.1/ui and you should see this login dialog:
Login using the “UI_USERNAME” and “UI_PASSWORD” that you configured. LiteLLM has many features, too many to fully cover here.
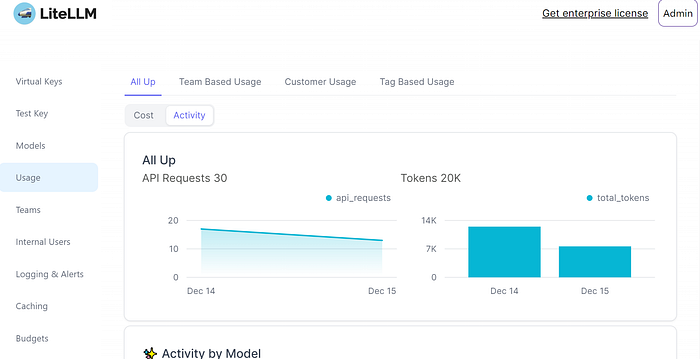
Monitoring Activity 🏃♂️
You can track API requests and token usage:
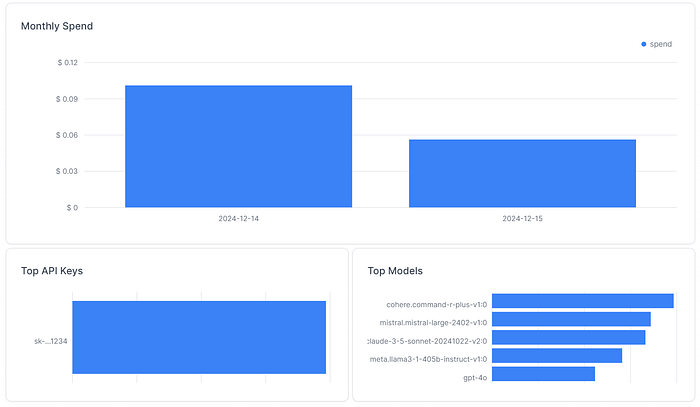
Monitoring Spend 💲
You can monitor the spend, by API key, Team, and model. Some metrics require acquiring an enterprise license.
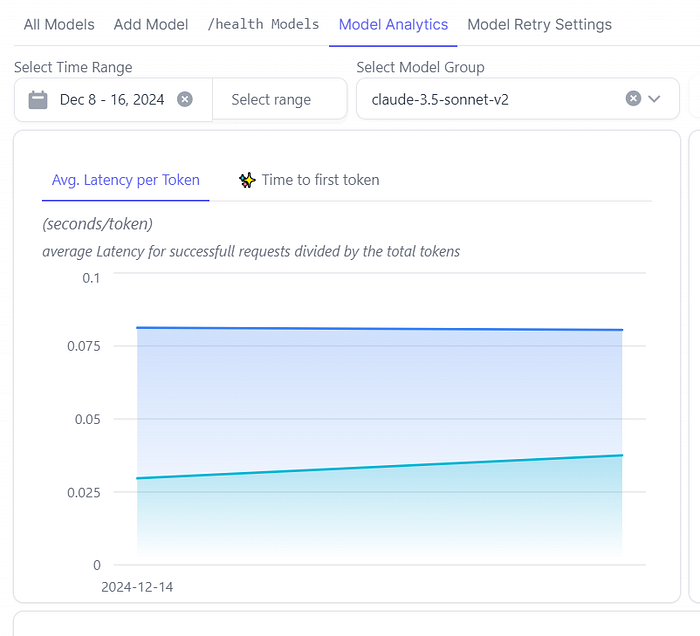
Monitoring Performance 🚀
Monitoring model performance and service latency.
Creating and Managing Users 🧑
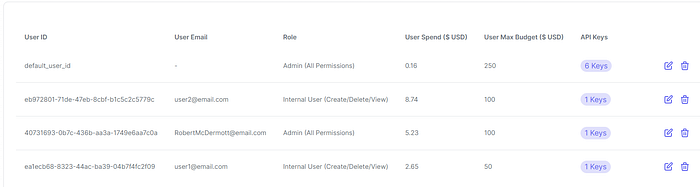
Creating and Managing Teams 👥
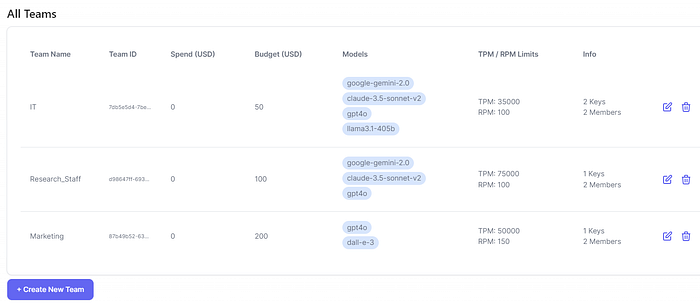
LiteLLM supports many other advanced features like SSO authentication, routing, load-balancing, logging, alerting and other capabilities. Some features require acquiring an enterprise license.
Integrating Open WebUI with LiteLLM
👉Note: I don’t cover installing Open WebUI in this article, please see my article titled “LLM Zero-to-Hero with Ollama” (specifically the section on Open WebUI) if you don’t already have a working Open WebUI instance.
Integration and Configuration 🧩
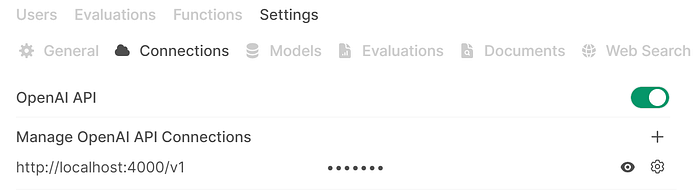
To add LiteLLM to your Open WebUI instance, log in with an account that has admin privileges, then go to “Admin Panel”, “Settings” then “Connections”. Enable “OpenAI API” then enter “http://localhost:4000/v1” (if you are running Open WebUI on a different host, enter the hostname of the LiteLLM server) with the master key you set earlier (or a virtual LiteLLM key you generated). See below:
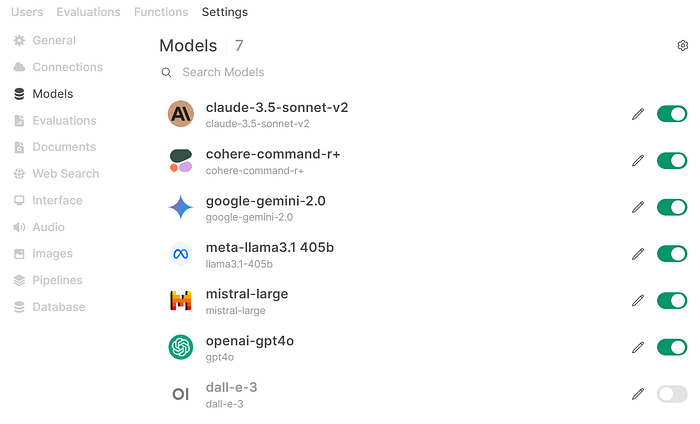
Now go to the “Settings / Models” configuration and refresh the page. You should see the models you configured listed. Disable the Dall-E-3 model as it’s not mean for text inference. In the image below, I’ve edited each model to assign the appropriate icon for each service/model. See below:
The the integration is complete, we are now ready to start prompting the models.
Prompting Models 💬
This doesn't require any explanation, it works just like most other chat AI applications. In this example below, I’ve selected three models, each from a different provider and ran a single prompt across all three in parallel for comparison:

Integrating Dall-E 3🎨
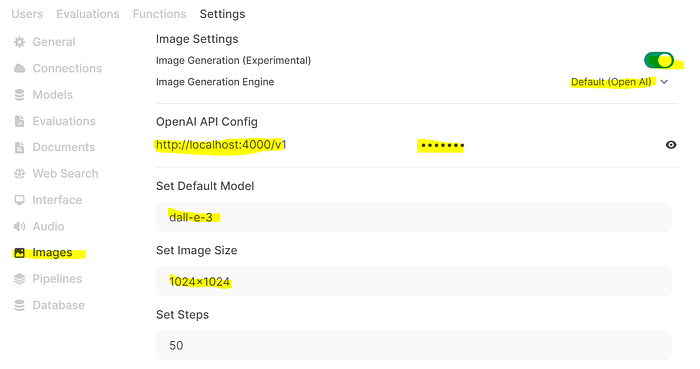
Before we can generate images, we need integrate the Azure/OpenAI Dall-E-3 service we’ve made available via LiteLLM with Open WebUI. Navigate to “Admin Panel”, then “Settings” then “Images”. Enable “Image Generation”, select “Default (Open AI)” put in the URL to the LiteLLM endpoint (http://localhost:4000/v1 in this article) and the LiteLLM master key (or other LiteLLM key you generated). Set the default model to “dall-e-3”, and change the image size to “1024x1024” (it was 512x512 by default but that doesn’t work with Dall-E version 3. See example below:
Generating Images 📷
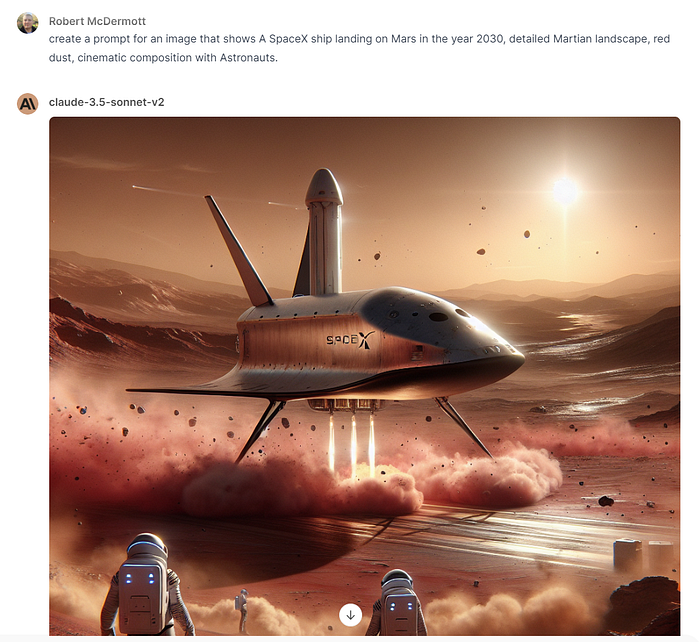
Image generation in Open WebUI is not straight forward. Rather than just entering a prompt, we instead have to use one of the other models to create an image prompt for use, then click on the “Generate Image” icon 🖼 on the response’s tool bar (high-lighted below). Here’s an example:

After we click the “Generate Image” icon, it will call Dall-e-3 and generate our requested image and place it at the top of the prompt response. What is coming out the stop of the spacecraft? 🤣:
Conclusion
In this article we covered installing, configuring and using LiteLLM to centralize the access to multiple AI services behind a single OpenAI compatible endpoint.
LiteLLM can be used at businesses to provide users and developers with secure access to any AI service, with control over model access, API key management, logging, alerting, rate limiting and can enforce user and team based spending limits.
🔥NOTE: if you are doing this for production use and will expose the endpoint and web UI to users on your network, you must put access behind an TLS proxy such as Nginx to ensure that all traffic is encrypted when traversing the network.
